We propose a 3D generalizable policy, RISE-2, to facilitate efficient learning from in-the-wild demonstrations and achieve robust task performance. The design of RISE-2 focuses on the precise feature fusion of 2D images and 3D point clouds to leverage the advantages of 2D vision in semantic information and 3D vision in spatial information simultaneously.
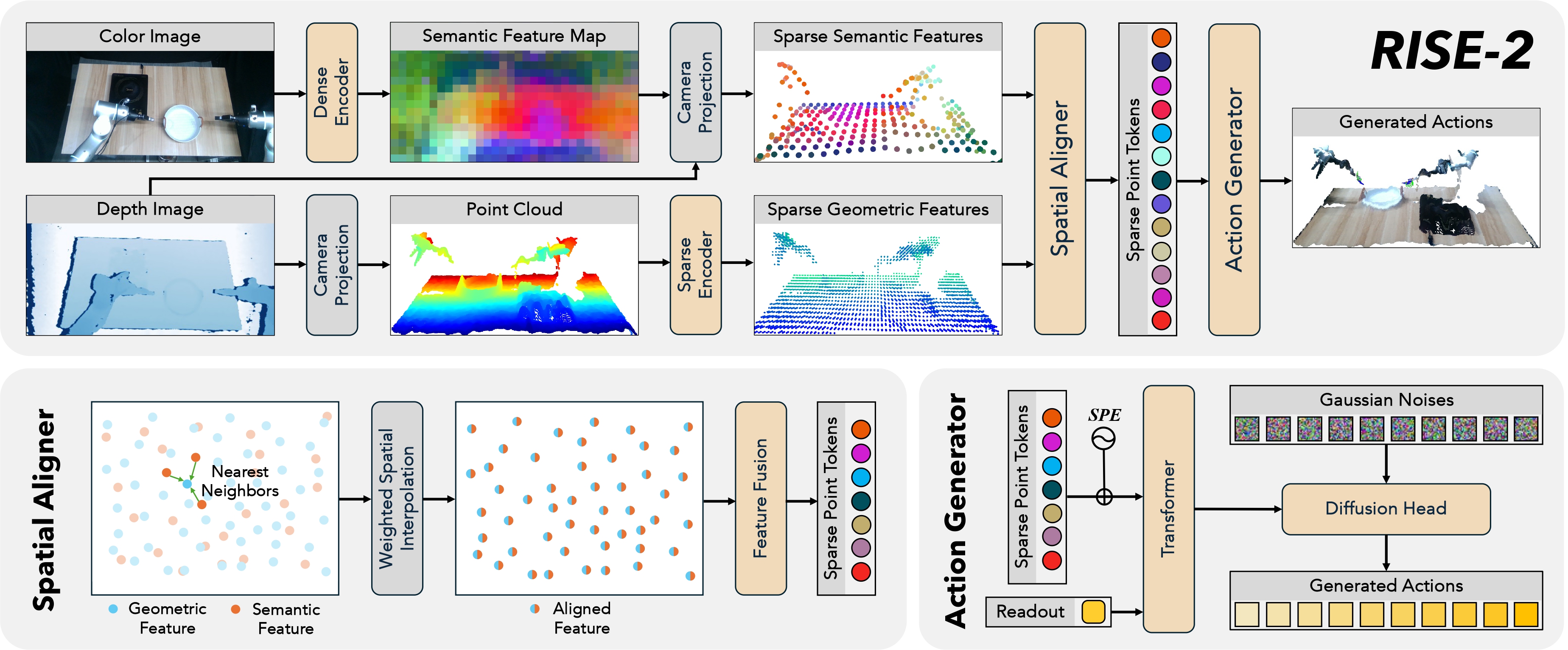
RISE-2 Policy Architecture. RISE-2 takes an RGB-D observation as input and generates continuous actions in the camera frame. It is composed of four modules: (1) the color image is fed into the dense encoder to obtain semantic features organized in 2D form, which is then projected to sparse 3D form using reference coordinates; (2) the depth image is transformed to a point cloud and fed into the sparse encoder to obtain the local geometric features of seed points; (3) in the spatial aligner, the semantic features and the geometric features are aligned and fused using their 3D coordinates; (4) in the action generator, the fused features are converted to sparse point tokens, mapped to action space using a transformer and sparse positional encoding (SPE), and decoded into continuous actions by a diffusion head.
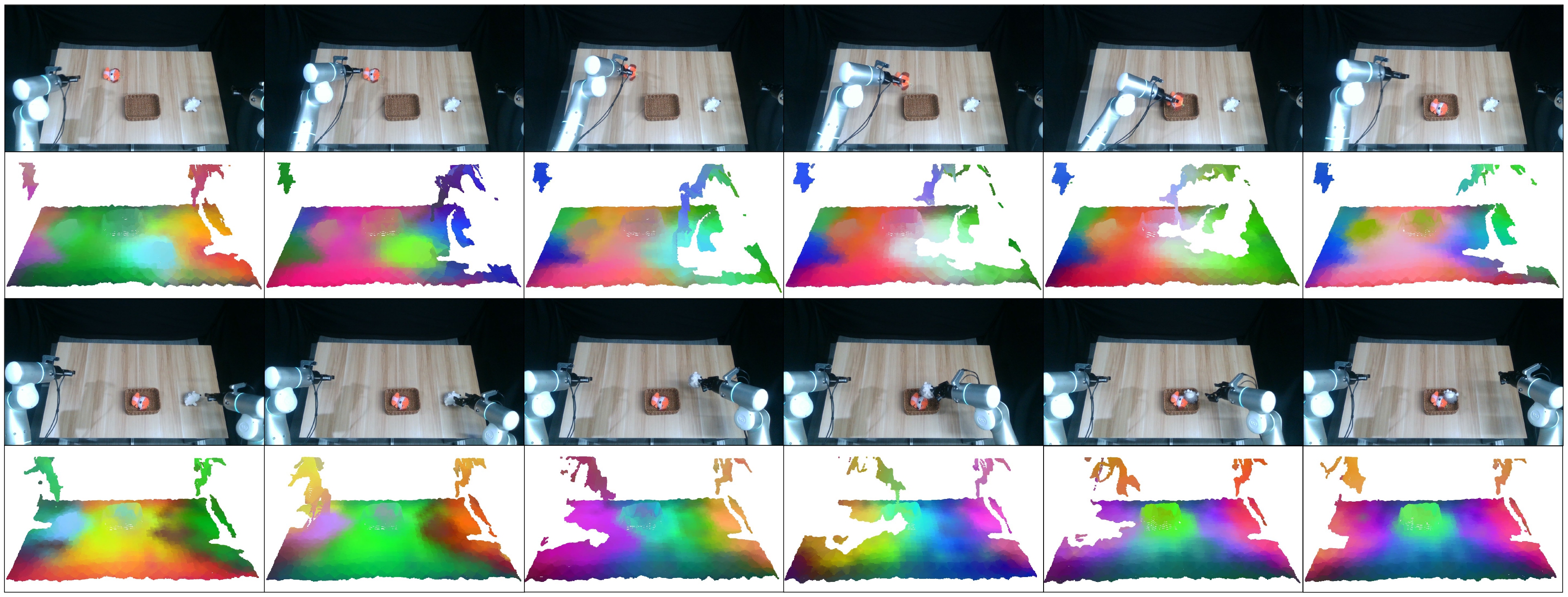
Visualization of Sparse Semantic Features. We observe clear and distinguishable continuous feature variations on the aligned features, where the targets at the current step can be easily identified from the entire scene. Such characteristic ensures precise feature fusion in the spatial domain. The features change significantly as the task progresses, enabling the model to clearly understand the global state at the current time.